Dead Letter Exchange Retrying - RabbitMQ
Use Case
At Community.com we use an event driven and event sourced architecture with RabbitMQ as our message broker. I won’t be explaining the nitty-gritty of how our event system works, since Karl Matthias already has, but I recommend reading it before continuing if you aren’t familiar with the pattern. The TLDR is: at Community, we produce and consume a lot of messages (think 10s of millions per day) that communicate information asynchronously across > 100 individual services.
The question is, what happens when a bad message gets in?
Good Scenario
Ideally, the flow will look something like this:
-
A message enters our consumers queue
-
Our consumer pops the message from the queue
-
Our consumer does its specific work (e.g. increment a number in a database)
-
Our consumer acknowledges the message
-
Rinse and repeat
If while doing the work (step 3) there was a temporary problem such as a small blip in network connectivity, a rolling upgrade of the consumer, etc… it wouldn’t be a problem since the message was never acknowledged by the consumer, the server will simply send it when another consumer connects. This happens dozens of times daily and we won’t alert (or need to know) unless we check the logs. Our system is highly available, and faults out of our control are expected and planned for.
Bad Scenario
However, what happens if there is a long term or permanent problem? Imagine a consumer doing any of the following:
- Expecting a nonexistent row to exist in a shared database
- Expecting a field that isn’t present in the message (think protobufs)
- Attempt to insert a 256 character string into a column that is
VARCHARcolumn with a length of 255. - Raising literally any uncaught error and causing the elixir process crash (an acceptable/recommended practice in elixir)
The first scenario may or may not resolve, depending on if the expected row eventually exists via another service. The rest of the examples will never resolve.
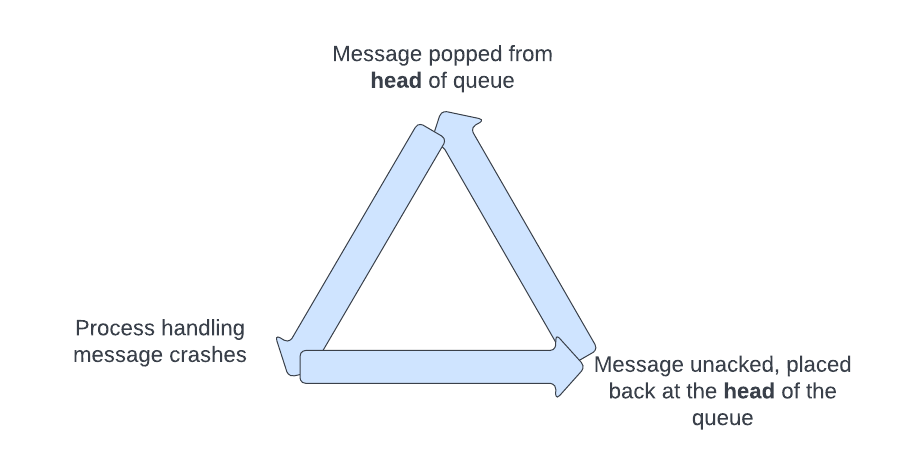
Our services are very fast, capable of handling thousands to tens of thousands of messages per service per second. When processing good messages, this is ideal for handling our spiky traffic and maintaining low latency end to end. When processing a bad (unprocessessable) message, it is immediately retried as fast as possible and continues doing so until manual intervention.
Problems
Before creating requirements for the service, we need to identity what exact problems we would like to address. These are in no specific order of importance.
Noise
So much noise. All sorts of noise: logs, alerts on said logs, high CPU usage, etc… A single unprocessable message can generate hundreds of thousands of lines of logs in a few short minutes. It looks like the sky is falling, even if it is a single unprocessable message. Noisy alerts make fatigued engineers.
Clogging
A message that fails and is returned to the queue returns to the head of the queue, not the tail. Imagine the following consumer setup:
- Consumer has a prefetch of 10 messages
- 10 bad messages get into the queue (many ways this is possible)
- 2 good messages get into the queue
In this case, since the prefetch is 10 and there are 10 bad messages, the queue is effectively “clogged”. No good messages will be processed since the first 10 items in the queue are constantly being retried. This is worse than attempting to process an unprocessable message, we are blocking good messages from being processed. The only way to fix this is to manually clear the “bad” messages.
Blind
Our messages are all Protobufs that are base64 encoded. This means, even if the log contains the contents of the bad message, we have to manually decode it and then attempt to match the binary protobuf data against all existing protobufs.
Not all messages are of equal importance. A message sent to increment the total number of texts sent in a month is not as important as a message sent to trigger a campaign. The former is not worth waking up an on-call engineer, but ideally can be slacked to them in the morning. The problem is the existing system is blind so we can’t make these choices.
Further, there is no way to “peek” the head of the queue. A message must be popped and requeued by hand in RabbitMQ. This means that the message must be in the queue and not held by a consumer that is constantly retrying it.
Requirements
Now that we have addressed issues with the current system, we needed to come up with requirements for a service to address these problems.
- The service must be as general as possible
- We have services in Elixir, Go, and Python
- The service should requeue a message at the end of a queue (tail)
- The service should have a configurable backoff
- The service should be able to tell how many times a specific message has been retried
- The service should use RabbitMQs’ dead letter exchange
- The service should be able to decode an arbitrary protobuf
- The service should send metrics of messages retried and permanently failed to a paging system
Dead Lettered Message
RabbitMQ dead letter exchange has a lot of information in there so I will summarize the parts that are relevant for our solution.
How is a message Dead Lettered
Simply put: when it is “dropped”. This occurs when a message is negatively acknowledged rather than acknowledged which the consumer should call after work is done.
NOTE: You may also see the term nack when looking into reject/negative acknowledgement. nack is an overloaded term, it is both an abbreviation for “negative acknowledge” as well as a method you can call to reject a group of messages in bulk.
Take a look at the following pseudocode for handling a message from the queue:
def handle_msg(channel, msg_id, payload):
do_work(payload)
channel.ack(msg_id)
The logic for implementing a basic “catch all” reject would be:
def handle_msg(channel, msg_id, payload):
try:
do_work(payload)
channel.ack(msg_id)
except:
channel.reject(msg_id)
Simple enough… We do some work on the message itself and then tell RabbitMQ we have processed the message, either successfully with ack or unsuccessfully with reject.
Our service will be responsible for handling these messages that have been rejected.
Metadata
A dead lettered message (i.e. rejected) contains a special x-death header that contains useful metadata about the message and where it came from. It will include data such as:
- Queue name -
queue - The number of times it has been dead lettered -
count- If a message with
x-deathis re-dead lettered, thecountautomatically increases
- If a message with
- The time the original message was dead lettered -
time - The reason it was dead lettered -
reason- Valid reasons:
rejected,expired,maxlen,delivery_limit
- Valid reasons:
This is the metadata required for our service.
Implementation
We want to implement the DLX Service in this sample architecture, where there are many Service Foos.
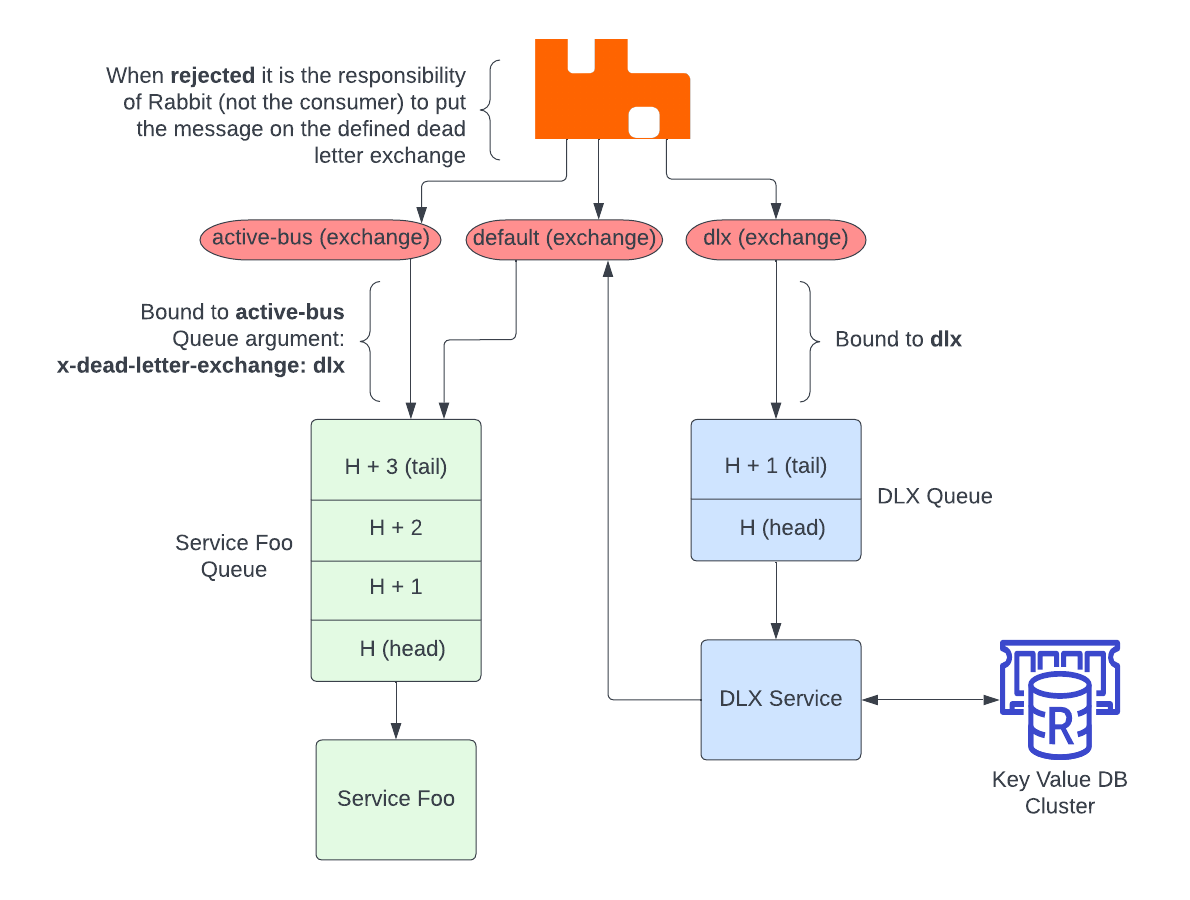
Here is the effective pseudocode (elixir style) for what we want to do. Don’t copy/paste this elixir, it probably won’t work.
@retries 3
defp consume(channel, tag, headers, payload) do
# extract the desired metadata from the headers
{queue, count} = extract_xdeath(headers)
if count == @retries do
# we are out of retries, log it, send a notification, etc
write_obituary(queue, payload)
else
# save the message for retrying later
save_for_retry(queue, count, headers, payload)
end
:ok = Basic.ack(channel, tag)
IO.puts "Processed message #{payload}."
end
Now, our code for save_for_retry is a bit clever. We must be able to support saving to/from source outside the service itself, since our service is containerized and may move to another node at any time. So what we do is save it in an HA Redis cluster where the key is the time at which we want to retry, and the value is the relevant metadata.
Something like this:
@retries [10, 100, 1000]
@redis Application.compile_env(redis_module)[:example]
defp save_for_retry(queue, count, headers, payload) do
# the key to save under
retry_time = unix_now_ms() + @retries[count - 1]
# the value
value = {queue, headers, payload}
@redis.save(retry_time, value)
end
This means we can handle any period of downtime of the service like during a cluster upgrade and still retry all messages since we won’t need a reliable “tick” time.
Finally, the “checking” and retrying code will look something like this (likely in the same module as the save_for_retry function):
defp tick(channel):
# get list of all messages scheduled to go out before or equal to now
to_retry = @redis.get_all_kv_lt_now()
for {queue, headers, payload} in to_retry:
# must republish headers so `count` can increase
Basic.publish(queue, "" = _direct_exchange, headers, payload)
schedule_tick(channel)
end
That’s pretty much it. I specifically call out that we are publishing on the direct exchange rather than the original one. This is because if the original exchange was a fanout we would republish to all queues bound to that exchange, not just the one that failed.
Changes To Existing Services
As mentioned in the requirements, the service we pseudo implemented above is intended to be simple and generic. Luckily, even though we use a few languages at Community, they all use wrapper libraries, so we can make the developer facing change a simple “opt-in” boolean like dlx: true.
The wrapper libraries themselves have slightly tweaked “consume” functions.
defp consume(channel, tag, headers, payload) do
# do normal work
do_work(payload)
# now we want to catch the exception rather than bubble up
rescue
exception ->
:ok = Basic.reject(channel, tag, requeue: false)
IO.puts "dead lettering #{payload}"
end
Manual Labor
Now there is unfortunately one manual “operator” step required when turning on dead lettering for an existing service. This stems from the idempotent nature of queues. Whenever a consumer opens a connection and channel, it doesn’t check if the queue it wants to consume from exists, it just declares it. This operation is idempotent and therefore always creates a queue if it doesn’t exist already. However, if the queue already exists, you can not change the attributes/properties of it; if you try, you will get a 406 - PRECONDITION_FAILED. We need to set the x-dead-letter-exchange property of the queue to tell Rabbit to put a rejected message on the dlx exchange (and therefore route to our service). We bounced around a handful of ideas to best approach this problem, but the easiest we could think of was: write a doc and make an alert.
The doc explains how to migrate an existing service to have dead lettering:
- Change the queue name (e.g. add a
_with_dlxsuffix) - Update your message wrapper version to at least version x.y.z
- Toggle the dlx option (
dlx: true) - Deploy
- Delete the old queue in the console by hand
This last step is the most important. If the old queue remains, it will continue to receive messages from the fanout exchanges and will eventually slow the entire RabbitMQ cluster down. Hence, the alert… we want to know if there are any queues without consumers, but we don’t want it to accidentally go off during an expected interruption like a rolling upgrade.
Something like this (the world’s first pseudo alert?):
SUM(CONSUMER COUNT) BY QUEUE_NAME FOR 15 MINUTES == 0
This will only alert if there have been no consumers on the queue for the past 15 minutes.
Conclusion
We have had this system running for the past ~6-9 months now on almost all of our clusters. It has saved us ~1-5 alerts per month from going off and still provides a very rare but real alert for a bad message.